大震災に備え我が家に備えておく救急箱に何を入れるべきか検討した記録です。
TL;DR
以下の用品が災害時に多い傷病に対する応急手当プロセスに必要でかつ救急箱に入るものです。:
かなり量が多いので次のような大型の救急箱でないと格納しきれません(2024/02/03追記: 紹介している救急箱はポリプロピレン製のため耐候性はありません。暗所に保存してください):
救急箱に入らないものの必要な用品に次のものがあります:
| 品名 |
数量 |
製品の例 |
| スマートフォン |
1つ |
- |
| 非常用ブランケット(乾いた毛布で代替可能) |
人数分 |
|
| 500mL 飲料水ペットボトル |
1本 |
|
| 日本全国AEDマップ |
1つ |
aedm.jp |
| 担架 |
1つ(身長より長い物干し竿と毛布で代替可能) |
|
上記のリストを満足する既製の救急用品セットは見つかりませんでした。個別に購入するのが面倒に感じた場合は上記の6割弱があらかじめ格納された次の救急用品セットを買うのでも買わないよりはマシだと思います:
これらの用品の使い方は各自治体の開催する上級救命講習で教われます。用品を備えるだけでは使い方がわからないので上級救命講習の受講も併せて検討するとよいでしょう。受講の時間が取れない方は 応急手当Web講習 - 総務省 を見るとよいでしょう。
なお上記のリストはあくまで無資格・無免許の一般市民が検討したものとご承知ください。信頼性の評価を第三者ができるように以下にこのリストの作成手法を説明します。
背景
著名な防災用品のチェックリスト*3*4は救急箱や救急セットを備えておくよう指示しています。しかしその中身への言及はごく僅かで何を用意しておけばいいのかわかりません。
過去には労働安全衛生規則が事業場に一律で備えるべき救急用具を規定していましたが、事業場ごとに負傷や疾病の発生状況が異なることから令和3年末にその規定は削除されました*5。
「救急箱 中身」で検索したトップヒットは 2006 年の総合南東北病院による「家庭用救急箱には何を用意すればいいのか?」でした。ただこれをみても (1) どの怪我に何を使うのかわからない、(2) 災害時の怪我に対応しきれるかわからない、という問題があります。その他ヒットしたWebサイトをみても同様の問題がありました。
そこでこの記事では災害時に多い怪我に対応できる応急手当のプロセスとそれを実現できる災害用救急箱の中身を検討します。なお私は医師免許、防災士のいずれの免許及び資格を所持していません。そのためここでの検討はあくまで無資格・無免許の一般市民によるものとご承知ください。
手法
次の7ステップで応急手当プロセスと災害用救急箱の中身を検討しました:
- 災害時に多い傷病を調べる
- それぞれに対応する応急手当プロセスを調べる
- 応急手当プロセスの初期成果物を洗い出す
- その他の目的の救急セットと比較し不足やよりよい代替品を洗い出す
- 3 と 4 をまとめて重複を取り除きつつ抽象的なものは具体的なものへと置き換える
- 災害時に使えなくなる成果物を代替する
- 救急箱に入るものと入らないものを分ける
STEP1. 災害時に多い傷病を調べる
行政によると地震による傷病の支配的な原因は家具類の転倒・落下・移動によるものだそうです:
地震のケガの原因の約30%~50%が、家具類の転倒・落下・移動によるものでした。
出典: 地震時の危険 - 東京消防庁
それ以外の原因についても調べてみました。阪神淡路大震災による怪我の内訳は次の通りのようです:
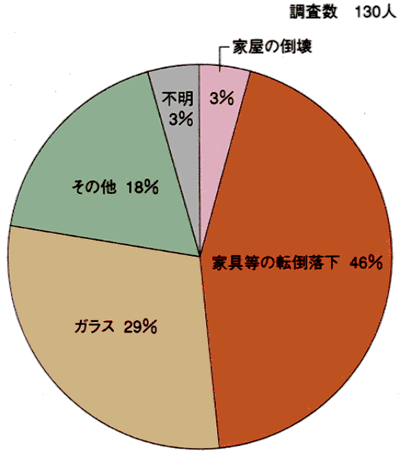
出典: 約6割の部屋で家具が転倒、散乱した - 消防庁
東日本大震災について死因は溺死が 90% を占めています*6。
記憶に新しい能登半島地震では次の通りでした:
死因で最も多かったのは、倒壊した建物の下敷きになったことなどによる「圧死」で、全体の41%にあたる92人、次いで、「窒息」や「呼吸不全」が49人(22%)でした。
さらに「低体温症」や「凍死」が32人(14%)にのぼり、真冬に起きた災害で、多くの人が救助を待つなどする間、寒さによって体力を奪われ、亡くなったとみられる実態が浮き彫りになりました。
出典: 能登半島地震の死因「圧死」92人「低体温症」や「凍死」32人 警察庁 専門家“過去の災害より多い印象 - NHK
これらをまとめると災害時に考慮すべき傷病の原因は以下の6つです:
- 家具類の転倒・落下・移動
- ガラス
- 家屋の倒壊
- 火災
- 溺水
- 低温
傷病の原因それぞれから発生しうる傷病を次のように推測しました:
| 原因 |
傷病 |
| 家具類の転倒・落下・移動 |
窒息 |
| 家具類の転倒・落下・移動 |
骨折・ひび |
| 家具類の転倒・落下・移動 |
打撲 |
| 家具類の転倒・落下・移動 |
切裂傷 |
| 家具類の転倒・落下・移動 |
捻挫・脱臼 |
| 家具類の転倒・落下・移動 |
熱傷 |
| ガラス |
切裂傷 |
| 家屋の倒壊 |
窒息 |
| 家屋の倒壊 |
骨折・ひび |
| 家屋の倒壊 |
打撲 |
| 家屋の倒壊 |
切裂傷 |
| 家屋の倒壊 |
捻挫・脱臼 |
| 火災 |
熱傷 |
| 溺水 |
窒息 |
| 低温 |
低体温症 |
これをまとめると対処したい傷病は次の7つです:
- 窒息
- 骨折・ひび
- 打撲
- 切裂傷
- 捻挫・脱臼
- 熱傷
- 低体温症
STEP2. それぞれに対応する応急手当プロセスを調べる
STEP1 で洗い出された傷病のそれぞれについて、救急隊または医療機関に引き継ぐまでに必要な手当(広義の応急手当)のプロセスを調べました。
応急手当のプロセスは「上級救命講習テキスト」(東京防災救急協会 版)をもとに PFD (Process Flow Diagram) で表現しました。上級救命講習テキストは各自治体が開催している上級救命講習のうち東京都が開催しているもののテキストです。上級救命講習とは成人・小児・乳児の心肺蘇生やAED、異物除去、止血法、傷病者管理、外傷の応急手当、搬送法などを学べる講習です(東京都の例)。つまりこのテキストに登場する救急用品の使用方法は上級救命講習を受講すると理解できると期待できます。
また表現方法として PFD を選んだ理由は、自然言語やフローチャートで表現されたプロセスは成果物を見落としやすいのに対して PFD では成果物が明示され成果物の不足を発見しやすいためです。成果物の不足はすべてのプロセスについて入力成果物から出力成果物を生成できるかを確認すると見抜けることが多いです。
ただ PFD は条件分岐の表現が苦手です。そのため今回は条件分岐を表現できる拡張を施した CPFD (Conditional PFD) を使いました。CPFD はオリジナルの PFD に条件分岐プロセスを追加した PFD の拡張です。CPFD に含まれるすべての条件分岐ノードへ値を割り当てるとその条件下の PFD を出力します。CPFD の初期成果物は生成されうるすべての PFD の初期成果物の合併になります。つまり震災時に発生しうる傷病それぞれの応急手当の CPFD の初期成果物の合併が救急箱に備えておくべき用品となります。
窒息の応急手当プロセス
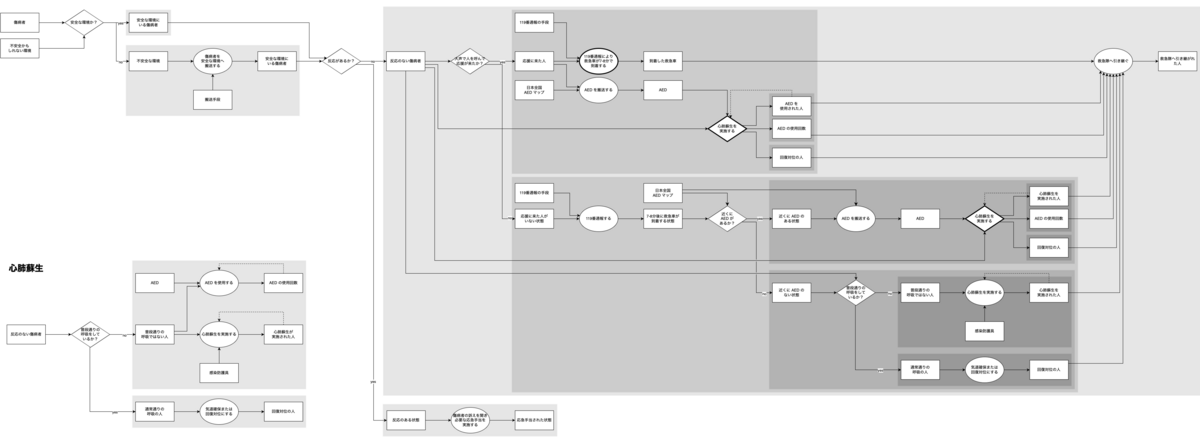 心肺蘇生プロセス
心肺蘇生プロセス
骨折・ひびの応急手当プロセス
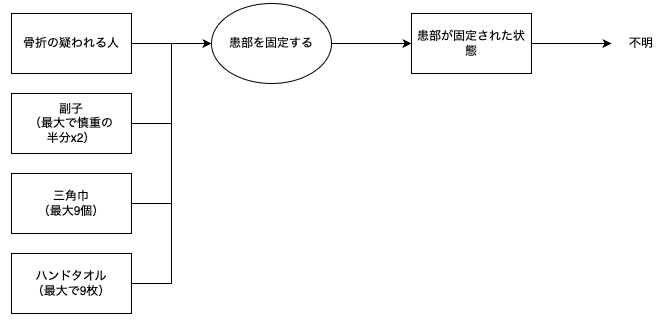 骨折の応急手当プロセス
骨折の応急手当プロセス
打撲の応急手当プロセス
上級救命講習テキストには打撲の応急手当プロセスの記述はありませんでした。そこで愛媛大学総合健康センターによる応急手当プロセス*7で代替しました:
 打撲・捻挫の応急手当プロセス
打撲・捻挫の応急手当プロセス
切裂傷の応急手当プロセス
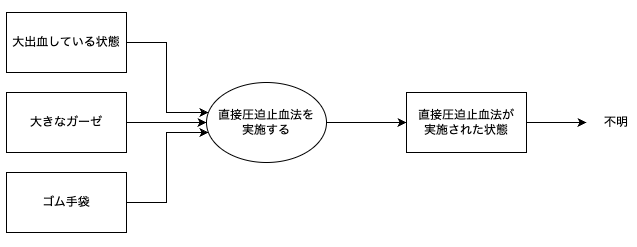 直接圧迫止血法のプロセス
直接圧迫止血法のプロセス
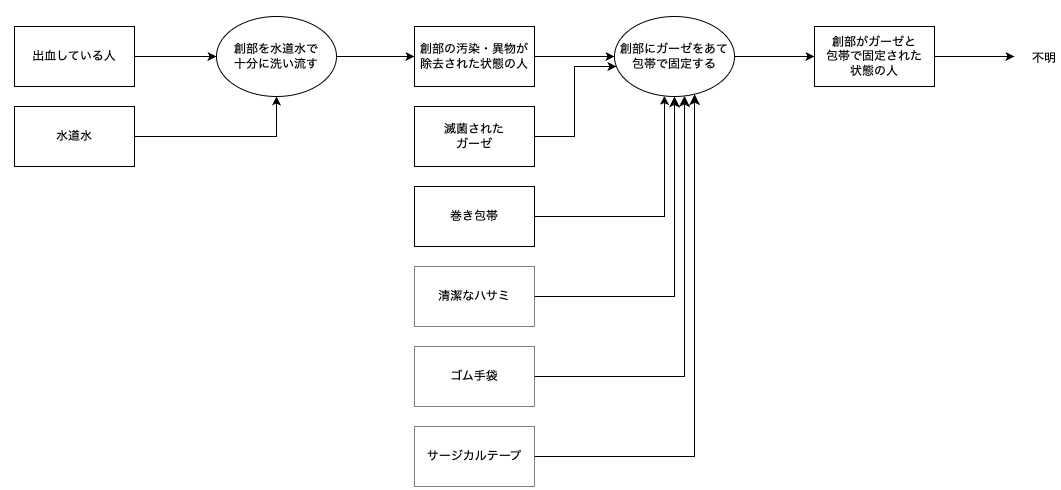 外傷の応急手当プロセス
外傷の応急手当プロセス
破線の成果物は上級救命講習テキストにはないものの手当に必要となるであろうと補完した用品です。
捻挫・脱臼の応急手当プロセス
上級救命講習テキストには捻挫・脱臼の応急手当プロセスの記述はありませんでした。そこで愛媛大学総合健康センターによる応急手当プロセス*8で代替しました:
打撲・捻挫の応急手当プロセス
熱傷の応急手当プロセス
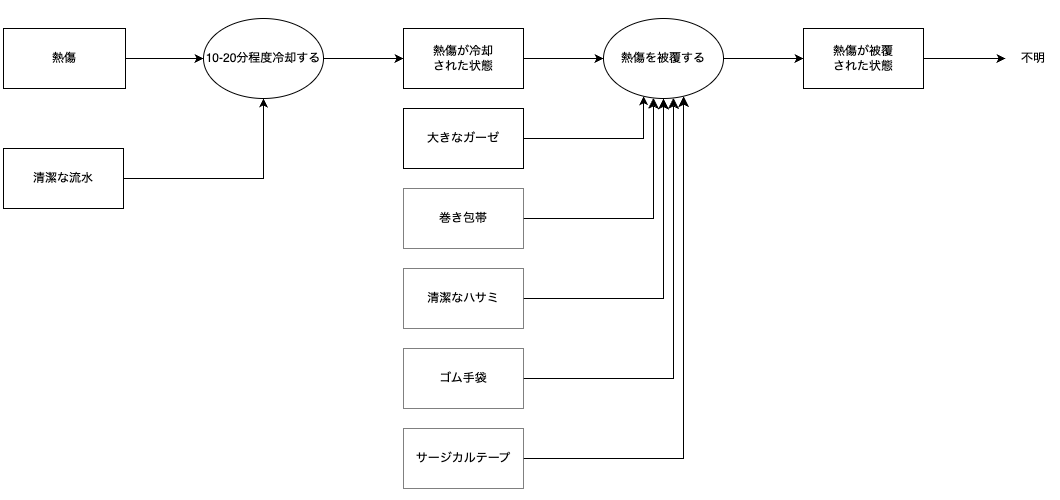 熱傷の応急手当プロセス
熱傷の応急手当プロセス
破線の成果物は上級救命講習テキストにはないものの手当に必要となるであろうと補完した用品です。
低体温症の応急手当プロセス
 低体温症の応急手当プロセス
低体温症の応急手当プロセス
STEP 3. 応急手当プロセスの初期成果物を洗い出す
これらの CPFD の初期成果物の一覧を以下に示します:
| プロセス |
傷病 |
初期成果物名 |
備考 |
| 心肺蘇生 |
心肺停止 |
傷病者 |
|
| 心肺蘇生 |
心肺停止 |
不安全かもしれない環境 |
|
| 心肺蘇生 |
心肺停止 |
搬送手段 |
|
| 心肺蘇生 |
心肺停止 |
119番通報の手段 |
|
| 心肺蘇生 |
心肺停止 |
日本全国AEDマップ |
|
| 心肺蘇生 |
心肺停止 |
感染防護具 |
|
| 直接圧迫止血法 |
大出血 |
大出血している人 |
|
| 直接圧迫止血法 |
大出血 |
大きなガーゼ |
タオルでもよい |
| 直接圧迫止血法 |
大出血 |
ゴム手袋 |
ビニール袋でもよい |
| 外傷の応急手当 |
外傷 |
出血している人 |
|
| 外傷の応急手当 |
外傷 |
水道水 |
|
| 外傷の応急手当 |
外傷 |
滅菌されたガーゼ |
滅菌された三角巾でもよい |
| 外傷の応急手当 |
外傷 |
巻き包帯 |
ネット包帯または三角巾でもよい |
| 外傷の応急手当 |
外傷 |
清潔なハサミ |
ガーゼを切るときに使う |
| 外傷の応急手当 |
外傷 |
サージカルテープ |
ガーゼの固定に使う |
| 外傷の応急手当 |
外傷 |
ゴム手袋 |
ガーゼの処置に使う |
| 骨折の応急手当 |
骨折 |
骨折の疑われる人 |
|
| 骨折の応急手当 |
骨折 |
副子 |
身長の半分のもの2つ |
| 骨折の応急手当 |
骨折 |
三角巾 |
9つ |
| 熱傷の応急手当 |
熱傷 |
熱傷 |
|
| 熱傷の応急手当 |
熱傷 |
清潔な流水 |
|
| 熱傷の応急手当 |
熱傷 |
清潔なガーゼ |
三角巾や清潔なタオル、シーツでもよい |
| 熱傷の応急手当 |
熱傷 |
清潔なハサミ |
ガーゼを切るときに使う |
| 熱傷の応急手当 |
熱傷 |
サージカルテープ |
ガーゼの固定に使う |
| 熱傷の応急手当 |
熱傷 |
ゴム手袋 |
ガーゼの処置に使う |
| 打撲・捻挫の応急手当 |
打撲 |
打撲または捻挫した人 |
|
| 打撲・捻挫の応急手当 |
打撲 |
氷水など |
|
| 打撲・捻挫の応急手当 |
捻挫 |
打撲または捻挫した人 |
|
| 打撲・捻挫の応急手当 |
捻挫 |
氷水など |
|
| 低体温症の応急手当 |
低体温症 |
乾いた衣服や毛布 |
|
| 低体温症の応急手当 |
低体温症 |
搬送手段 |
|
| 低体温症の応急手当 |
低体温症 |
低体温症の疑われる人 |
|
STEP4. その他の目的の救急セットと比較して不足やよりよい代替品を洗い出す
経験的に登山用、軍用およびライフセーバーの救急セットには収納容積が小さく効率的な用品が入っていることが多いためそれらを調べ不足や代替品を洗い出しました。
登山用の救急セット
【現役ガイド直伝】 登山初級者でも安心「実用的ファーストエイドキット」を大公開! - YAMA HACK と 持たない理由がない!非常時以外でも使えるエマージェンシーシートの実力が侮れない・・・ - YAMAHACK を参考に STEP5 の内容に加えて以下の4+1用品が洗い出されました:
- 棘ぬき
- サムスプリント(副子の一種)
- 手指消毒用アルコール
- 穴の空いたペットボトルの蓋
- 非常用ブランケット
軍用の救急セット
米軍の応急処置キットIFAK - ミリタリーショップレプマート を参考に STEP5 の内容に加えて以下の用品が洗い出されましたが、それぞれに付記した理由で代替品とは見做しませんでした:
- CAT ターニケット(止血帯)
- 上級救命講習によれば訓練されていないバイスタンダーに止血帯法は推奨されていません。そのため代替品から取り除きました
- 経鼻エアウェイ
- 上級救命講習では気道確保の手法として頭部後屈あご先挙上法が指示されています。また 経鼻エアウェイの挿入 - MSDマニュアル を読む限り非医療従事者が扱えるものとは思えませんでした。そのため代替品から取り除きました
ライフセーバーの救急セット
ライフセーバーの用品として CPR ボードがあるようです。これは気道確保と胸骨圧迫をやりやすくするためのものです。
STEP5. STEP3, 4 の成果物をまとめて重複を取り除きつつ抽象的なものは具体的なものへと置き換える
STEP3, 4 の成果物をまとめて重複を取り除き、抽象的なものは具体的なものへと置き換えました:
| 品名 |
まとめた品名または具体化した品名 |
| ゴム手袋 |
|
| サージカルテープ |
|
| 巻き包帯 |
|
| 感染防護具 |
|
| 三角巾 |
|
| 清潔なハサミ |
|
| 大きなガーゼ |
|
| サムスプリント |
副子 |
| 滅菌されたガーゼ |
清潔なガーゼ |
| 棘ぬき |
|
| 手指消毒用アルコール |
|
| スマートフォン |
119番通報の手段 |
| 乾いた衣服や毛布 |
|
| 非常用ブランケット |
|
| 清潔な流水 |
水道水 |
| 日本全国AEDマップ |
|
| 担架 |
搬送手段 |
| 氷水 |
|
STEP6. 災害時に使えなくなる成果物を代替する
災害時は断水および停電になりうるため、それによって使用できなくなりうる品を代替品に取り替えました:
| 品名 |
断水・停電時に使えなくなる品名 |
| ゴム手袋 |
|
| サージカルテープ |
|
| 巻き包帯 |
|
| 感染防護具 |
|
| 三角巾 |
|
| 清潔なハサミ |
|
| 大きなガーゼ |
|
| サムスプリント |
|
| 滅菌されたガーゼ |
|
| 棘ぬき |
|
| 手指消毒用アルコール |
|
| 119番通報の手段 |
|
| 乾いた衣服や毛布 |
|
| 非常用ブランケット |
|
| 500mL 飲料水ペットボトル*9 |
清潔な流水, 氷水 |
| 穴の空いたペットボトルの蓋 |
清潔な流水, 氷水 |
| 日本全国AEDマップ |
|
| 担架 |
|
STEP7. 救急箱に入るものと入らないものを分ける
次の大きめの救急箱を目安に救急箱に入るものと入らないものを分けました。数量は CPFD の備考をもとにしています:
| 品名 |
救急箱に入れられる |
数量 |
| ゴム手袋 |
o |
1組 |
| サージカルテープ |
o |
1本 |
| 巻き包帯 |
o |
1本 |
| 感染防護具 |
o |
1つ |
| 三角巾 |
o |
9つ |
| 清潔なハサミ |
o |
1本 |
| 大きなガーゼ |
o |
1枚 |
| サムスプリント |
o |
2本 |
| 滅菌されたガーゼ |
o |
1枚 |
| 棘ぬき |
o |
1本 |
| 手指消毒用アルコール |
o |
1つ |
| 穴の空いたペットボトルの蓋 |
o |
1つ |
| スマートフォン |
x |
1つ |
| 乾いた衣服や毛布 |
x |
人数分 |
| 非常用ブランケット |
x |
人数分 |
| 500mL 飲料水ペットボトル |
x |
1本 |
| 日本全国AEDマップ |
x |
1つ |
| 担架 |
x |
1つ |
こうして冒頭の救急用品のリストが出来上がりました。またその救急用品をどのように使うかを明らかにできました。
おわりに
これらの用品の使い方は各自治体の開催する上級救命講習で教われます。用品を備えるだけでは使い方がわからなくていざという時に困ります。上級救命講習の受講も併せて検討するとよいでしょう。上級救命講習の申し込み方法についてはお住まいの各自治体にお問い合わせください。実習の時間を捻出できない方は 応急手当Web講習 - 総務省 を見るとよいでしょう。
またそもそも家具の転倒や家屋の倒壊、火災を予防するための準備が有効であることはいうまでもありません。家具の固定、家屋の耐震補強、消火器の設置、感震ブレーカーの設置を進めていきましょう。


![[マツヨシ] 使い捨て手袋 ニトリルグローブ ホワイト 粉なし 100枚入り 病院採用商品 (松吉医科器械) (M, 新パッケージ) (M)](https://m.media-amazon.com/images/I/41343nyYbJL._SL500_.jpg "[マツヨシ] 使い捨て手袋 ニトリルグローブ ホワイト 粉なし 100枚入り 病院採用商品 (松吉医科器械) (M, 新パッケージ) (M)")

 1巻入り×2セット")
")






")

 ポリエステル エマージェンシーブランケット オレンジ 1人用 12132")

 日本縫製")